Vanilla Transformers¶
In the seminal paper Attention is All You Need, the legendary transformer architecture was born3.
Quote from Attention Is All You Need
"... the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output."
Transformer has evolved a lot in the past few years and there are a galaxy of variants4.
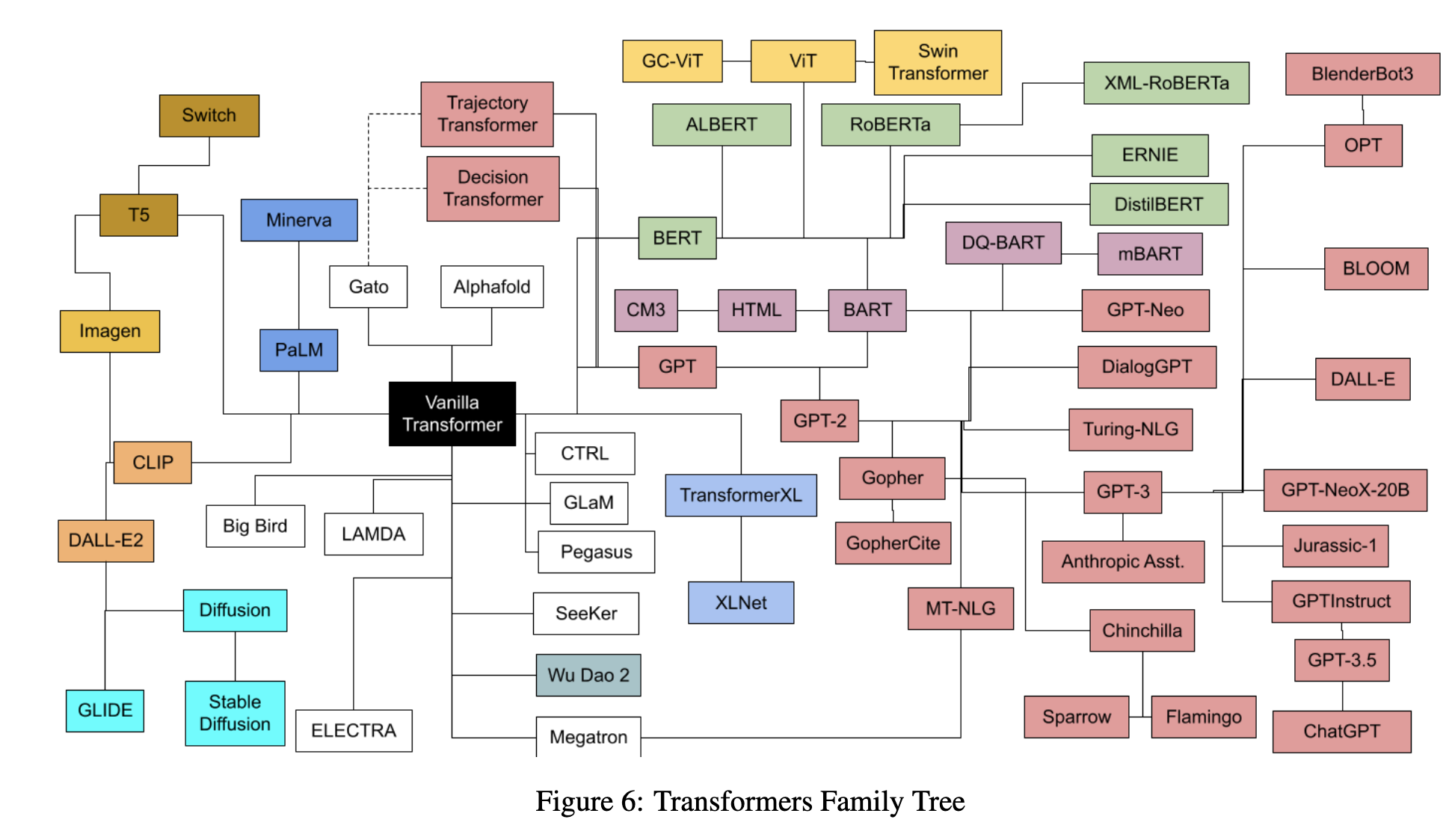
In this section, we will focus on the vanilla transformer. Jay Alammar wrote an excellent post, named The Illustrated Transformer1. We recommend the reader read the post. We won't cover everything in this section. However, for completeness, we will summarize some of the key ideas of transformers.
Formal Algorithms
For a formal description of the transformer-relevant algorithms, please refer to Phuong & Hutter (2022)5.
The Vanilla Transformer¶
In the vanilla transformer, we can find three key components: Encoder-Decoder, the attention mechanism, and the positional encoding.
Encoder-Decoder¶
It has an encoder-decoder architecture.
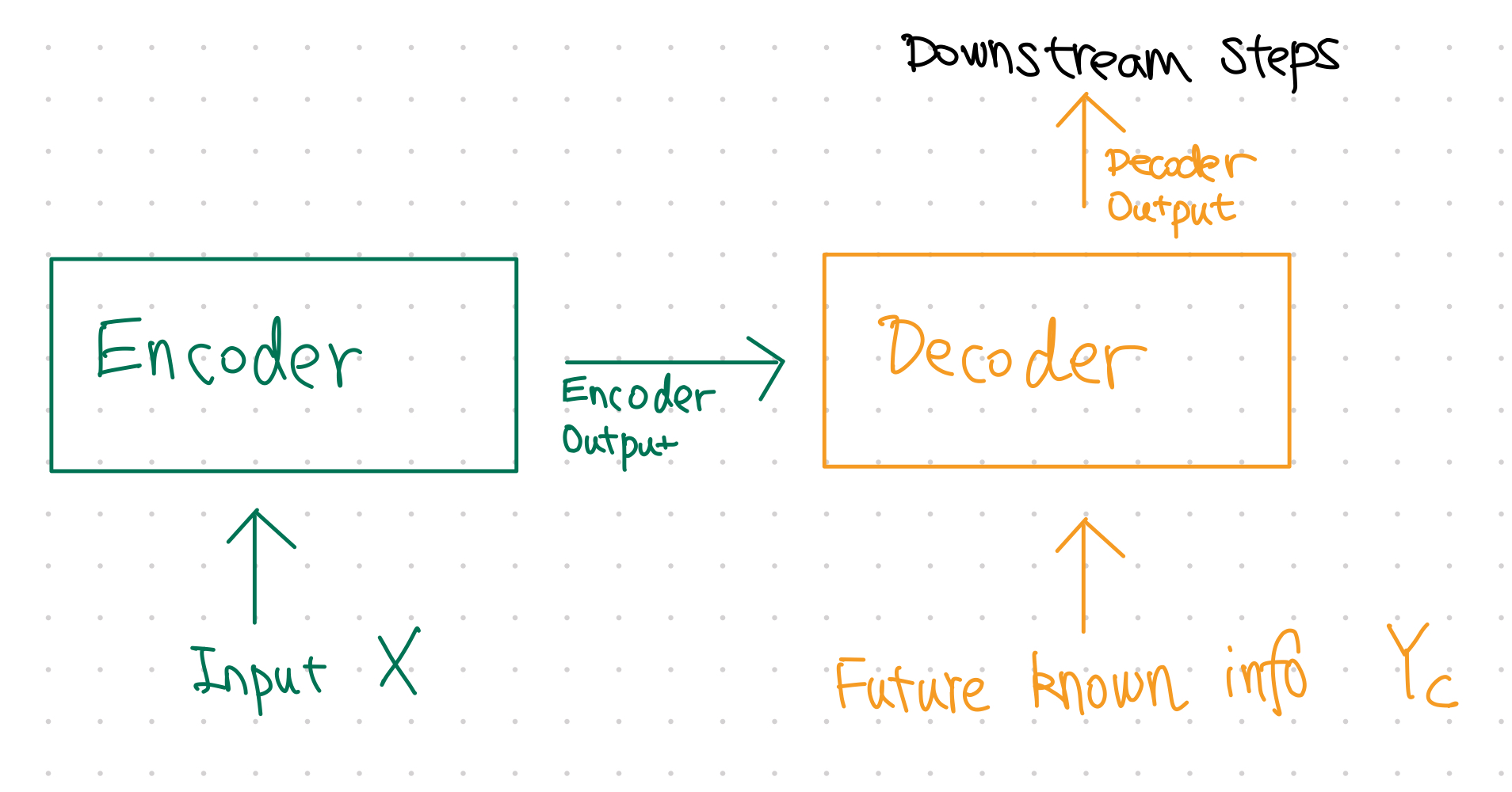
We assume that the input \(\mathbf X\) is already embedded and converted to tensors.
The encoder-decoder is simulating the induction-deduction framework of learning. Input \(\mathbf X\) is first encoded into a representation \(\hat{\mathbf X}\) that should be able to capture the minimal sufficient statistics of the input. Then, the decoder takes this representation of minimal sufficient statistics \(\hat{\mathbf X}\) and perform deduction to create the output \(\hat{\mathbf Y}\).
Attention¶
The key to a transformer is its attention mechanism. It utilizes the attention mechanism to look into the relations of the embeddings36. To understand the attention mechanism, we need to understand the query, key, and value. In essence, the attention mechanism is a classifier that outputs the usefulness of the elements in the value, and the usefulness is represented using a matrix formed by the query and the key.
where \(d_k\) is the dimension of the key \(\mathbf K\). For example, we can construct the query, key, and value by applying a linear layer to the input \(\mathbf X\).
Conventions
We follow the convention that the first index of \(\mathbf X\) is the index for the input element. For example, if we have two words as our input, the \(X_{0j}\) is the representation of the first word and \(X_{1j}\) is that for the second.
We also use Einstein notation in this section.
| Name | Definition | Component Form | Comment |
|---|---|---|---|
| Query \(\mathbf Q\) | \(\mathbf Q=\mathbf X \mathbf W^Q\) | \(Q_{ij} = X_{ik} W^{Q}_{kj}\) | Note that the weights \(\mathbf W^Q\) can be used to adjust the size of the query. |
| Key \(\mathbf K\) | \(\mathbf K=\mathbf X \mathbf W^K\) | \(K_{ij} = X_{ik} W^{K}_{kj}\) | In the vanilla scaled-dot attention, the dimension of key is the same as the query. This is why \(\mathbf Q \mathbf K^T\) works. |
| Value \(\mathbf V\) | \(\mathbf V = \mathbf X \mathbf W^V\) | \(V_{ij} = X_{ik} W^{V}_{kj}\) |
The dot product \(\mathbf Q \mathbf K^T\) is
which determines how the elements in the value tensor are mixed, \(A_{ij}V_{jk}\). For identity \(\mathbf A\), we do not mix the rows of \(\mathbf V\).
Classifier
The dot-product attention is like a classifier that outputs the usefulness of the elements in \(\mathbf V\). After training, \(\mathbf A\) should be able to make connections between the different input elements.
We will provide a detailed example when discussing the applications to time series.
Knowledge of Positions¶
Positional information, or time order information for time series input, is encoded by a positional encoder that shifts the embeddings. The simplest positional encoder uses the cyclic nature of trig functions3. By adding such positional information directly to the values before the data flows into the attention mechanism, we can encode the positional information into the attention mechanism2.
-
Alammar J. The Illustrated Transformer. In: Jay Alammar [Internet]. 27 Jun 2018 [cited 14 Jun 2023]. Available: http://jalammar.github.io/illustrated-transformer/ ↩
-
Kazemnejad A. Transformer Architecture: The Positional Encoding. In: Amirhossein Kazemnejad’s Blog [Internet]. 20 Sep 2019 [cited 7 Nov 2023]. Available: https://kazemnejad.com/blog/transformer_architecture_positional_encoding/ ↩
-
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN et al. Attention is all you need. 2017.http://arxiv.org/abs/1706.03762. ↩↩↩
-
Amatriain X. Transformer models: An introduction and catalog. arXiv [csCL] 2023. doi:10.48550/ARXIV.2302.07730. ↩
-
Phuong M, Hutter M. Formal algorithms for transformers. 2022. doi:10.48550/ARXIV.2207.09238. ↩
-
Zhang A, Lipton ZC, Li M, Smola AJ. Dive into deep learning. arXiv preprint arXiv:210611342 2021. ↩