Denoising Diffusion Probabilistic Models¶
Many philosophically beautiful deep learning ideas face the tractability problem. Many deep learning models utilize the concept of latent space, e.g., \(\mathbf z\), which is usually a compression of the real data space, e.g., \(\mathbf x\), to enable easier computations for our task.
However, such models usually require the computation of an intractable marginalization of the joint distribution \(p(\mathbf x, \mathbf z)\) over the latent space3. To make such computations tractable, we have to apply approximations or theoretical assumptions. Diffusion models in deep learning establish the connection between the real data space \(\mathbf x\) and the latent space \(\mathbf z\) assuming invertible diffusion processes 4 5.
Objective¶
In a denoising diffusion model, given an input \(\mathbf x^0\) drawn from a complicated and unknown distribution \(q(\mathbf x^0)\), we find
- a latent space with a simple and manageable distribution, e.g., normal distribution, and
- the transformations from \(\mathbf x^0\) to \(\mathbf x^n\), as well as
- the transformations from \(\mathbf x^n\) to \(\mathbf x^0\).
Image Data Example
The following figure is taken from Sohl-Dickstein et al. (2015)5.
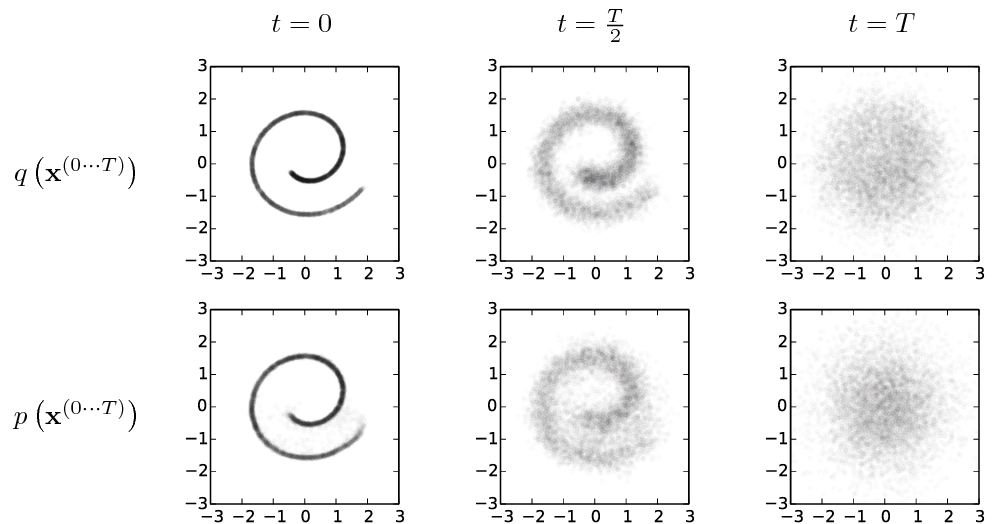
The forward process, shown in the first row, diffuses the original spiral data at \(t=0\) into a Gaussian noise at \(t=T\). The reverse process, shown in the second row, recovers the original data from \(t=T\) into the image at \(t=0\).
In the following texts, we use \(n\) instead of \(t\).
An Example with \(N=5\)¶
For example, with \(N=5\), the forward process is
flowchart LR
x0 --> x1 --> x2 --> x3 --> x4 --> x5and the reverse process is
flowchart LR
x5 --> x4 --> x3 --> x2 --> x1 --> x0The joint distribution we are searching for is
A diffusion model assumes a simple diffusion process, e.g.,
This simulates an information diffusion process. The information in the original data is gradually smeared.
If the chosen diffusion process is reversible, the reverse process of it can be modeled by a similar Markov process
This reverse process is the denoising process.
As long as our model estimates \(p_\theta (\mathbf x^n \vert \mathbf x^{n-1})\) nicely, we can go \(\mathbf x^0 \to \mathbf x^N\) and \(\mathbf x^N \to \mathbf x^0\).
The Reverse Process: A Gaussian Example¶
With Eq \(\eqref{eq-guassian-noise}\), the reverse process is
Summary¶
- Forward: perturbs data to noise, step by step;
- Reverse: converts noise to data, step by step.
flowchart LR
prior["prior distribution"]
data --"forward Markov chain"--> noise
noise --"reverse Markov chain"--> data
prior --"sampling"--> noiseOptimization¶
The forward chain is predefined. To close the loop, we have to find \(p_\theta\). A natural choice for our loss function is the negative log-likelihood,
(Ho et al., 2020) proved that the above loss has an upper bound related to the diffusion process defined in Eq \(\eqref{eq-guassian-noise}\)1
where \(\epsilon\) is a sample from \(\mathcal N(0, \mathbf I)\). The second step assumes the Gaussian noise in Eq \(\eqref{eq-guassian-noise}\), which is equivalent to1
with \(\alpha_n = 1 - \beta _ n\), \(\bar \alpha _ n = \Pi _ {i=1}^n \alpha_i\), and \(\Sigma_\theta\) in Eq \(\eqref{eqn-guassian-reverse-process}\).
Code¶
Rogge & Rasul (2022) wrote a post with detailed annotations of the denoising diffusion probabilistic model2.
-
Rasul K, Seward C, Schuster I, Vollgraf R. Autoregressive Denoising Diffusion Models for Multivariate Probabilistic Time Series Forecasting. arXiv [cs.LG]. 2021. Available: http://arxiv.org/abs/2101.12072 ↩↩
-
Rogge N, Rasul K. The Annotated Diffusion Model. In: Hugging Face Blog [Internet]. 7 Jun 2022 [cited 18 Feb 2023]. Available: https://huggingface.co/blog/annotated-diffusion ↩
-
Luo C. Understanding diffusion models: A unified perspective. 2022.http://arxiv.org/abs/2208.11970. ↩
-
Sohl-Dickstein J, Weiss EA, Maheswaranathan N, Ganguli S. Deep unsupervised learning using nonequilibrium thermodynamics. 2015.http://arxiv.org/abs/1503.03585. ↩
-
Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models. 2020.http://arxiv.org/abs/2006.11239. ↩↩